![]()
![]()
![]()
![]()
Data-driven research in materials science requires a reliable and flexible infrastructure capable of managing diverse experimental data. Within the Materials Discovery and Interfaces chair, the Data Science Group is committed to supporting the entire data science lifecycle. This spans everything from the initial collection of raw data to the deployment of predictive models trained on curated, integrated datasets. The group’s work is rooted in the development of flexible and extensible software platforms tailored to the specific needs of high-throughput materials screening and research at MDI, as well as the maintenance of the supporting infrastructure, both hardware and software.
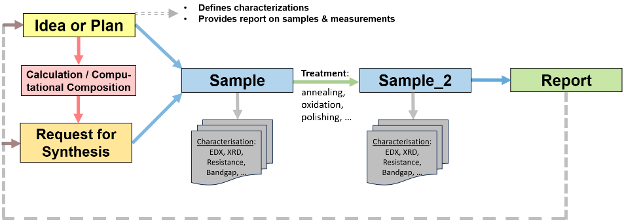
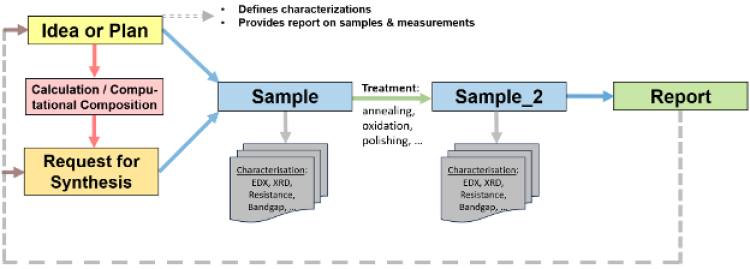
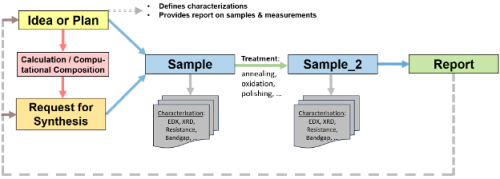
A central focus of the group is research data management—designing and implementing software systems that ensure research data remains findable, accessible, interoperable, and reusable. We develop the MatInf Research Data Management System, a flexible and extensible platform that enables researchers not only to efficiently capture and process data but also to maintain its quality, consistency, and security throughout its lifecycle. Dedicated tools for data analysis and visualization are developed as modular extensions that integrate seamlessly into the RDMS web application, ensuring a smooth and cohesive user experience. This work includes defining data governance policies, implementing validation and standardization procedures to monitor data quality, and ensuring secure, role-based access to sensitive datasets. In parallel, we are responsible for preserving metadata, tracking data lineage, and supporting long-term data usability and transparency.
Another key aspect of the group's work is the integration of data from heterogeneous sources, including a variety of high-throughput synthesis and characterisation instruments, which will be extended to (semi)autonomous experimental platforms. Our infrastructure supports the seamless consolidation of this data into unified, consistent datasets suitable for advanced analysis. We further empower external research teams by providing APIs, tools, and interactive environments that facilitate data exploration and interpretation, supporting both accessibility and scientific rigor.
The group operates a fully autonomous full-stack infrastructure—managing physical servers and networks while designing, building, and deploying domain-specific software solutions. This independence allows for rapid prototyping and continuous development of platforms precisely adapted to the evolving requirements of materials science research, without relying solely on generic off-the-shelf solutions. To support long-term data sustainability, we collaborate with NFDI initiatives, including FAIRmat (for integration with NOMAD), NFDI-MatWerk (to establish semantic interoperability), and Coscine (for long-term data archiving).
By combining strategic leadership in high-throughput data management, with a focus on experimental data and the aim to make a fusion of computational and experimental data, with deep technical expertise in software and infrastructure development, the group plays a dual role. On one hand, we define and implement research data policies and best practices; on the other, we are directly involved in the design, deployment, and long-term support of the technical systems that bring those strategies to life.
This combined perspective is reflected in MatInf, which serves as the cornerstone of our vision for a comprehensive Materials Data Integration Platform. Built around our in-house Research Data Management System, this platform reflects both the scientific ambition and the technical foundation of our work.
Copyright © mdi 2025
Last update: Jun 04, 2025

{kind=link}
{kind=link}
{kind=link}